

Кристоф Адам
Новые мостовые микросхемы дают возможность создания мультипроцессирующих, интеллектуальных устройств ввода/вывода, которые устраняют многие из ограничений, связанных с использованием шин PCI и CompactPCI в реальном масштабе времени.
Изначально быстродействующая шина PCI была разработана для применения в персональных компьютерах. Однако в последнее время шина PCI в той или иной форме все чаще находит применение во встроенных системах. Наиболее популярным здесь является электрический и логический эквивалент шины PCI CompactPCI с его надежным и проверенным форматом Eurocard. В настоящее время разработчики применяют различные методы, позволяющие производить мультиобработку в реальном масштабе времени с использованием так называемых мостов PCI-PCI (PPB).
Разработчики должны четко дифференцировать устройства с симметричной и асимметричной мультиоб-работкой. При асимметричной мультиобработке через шину PCI/CompactPCI связываются несколько PCI-плат. Каждая такая плата является "интеллектуальной", она имеет свой собственный процессор и операционную систему. Базовая конфигурация реализует пользовательский интерфейс и сетевую часть системы на основе главного процессора с дополнительными модулями ввода/вывода, обеспечивающими обработку в реальном масштабе времени (рис. 1).
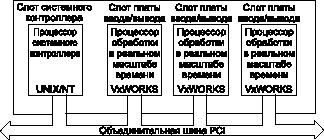
Рис. 1. Базовая конфигурация шины PCI или CompactPCI реализует пользовательский интерфейс и сетевую часть системы из системного контроллера и дополнительных модулей ввода/вывода, обеспечивающих дополнительную обработку в реальном масштабе времени
С другой стороны, при симметричной мультиобработке несколько процессоров объединяются на одной общей процессорной шине под управлением одной операционной системы, которая распределяет независимые потоки между несколькими процессорами. Симметричная мультиобработка происходит только на процессорной шине и выполняется независимо от шины PCI или других шин ввода/вывода. В данной статье рассматриваются проблемы только асимметричной мультиобработки.
PCI/CompactPCI система должна иметь центральный контроллер, который вырабатывает синхросигналы для шины PCI, управляет конфигурацией, обеспечивает арбитраж и обрабатывает прерывания. Синхронная шина PCI требует, чтобы контроллер системы вырабатывал единый синхросигнал для всей системы. Процессор передает этот синхросигнал на локальную шину PCI через мост процессор-PCI, изображенный в верхней части рис. 2. В системе CompactPCI процессор передает локальный PCI синхросигнал на шину, которая распределяет синхросигнал между другими платами в системе.
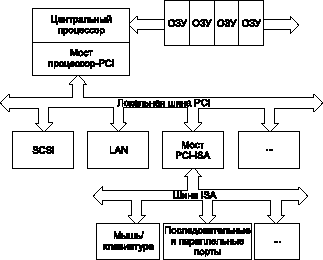
Рис. 2. В базовой PCI архитектуре процессор вырабатывает синхросигналы на локальную шину PCI через мост процессор-PCI в верхней части рисунка
И устройства PCI, и CompactPCI имеют определенные аппаратные и программные спецификации, накладывающие требования на цикл автоконфигурации, чтобы обеспечить совместимость с технологией plug-and-play. При включении питания системы начинается процедура определения ее конфигурации. Во время выполнения этой процедуры центральный контроллер системы использует специальную шину, чтобы обнаружить те устройства PCI, которые соединяются с ее локальной шиной PCI, и те, которые соединяются с другими шинами PCI через мосты PPB. Затем он конфигурирует систему и назначает адресные диапазоны для ее локальных устройств PCI, для PPB, а также для любых устройств PCI, найденных на объединительных платах PCI позади PPB.
Поскольку шина PCI является многоабонентской шиной, несколько разных устройств могут конкурировать за ее управление через механизм запросов. Центральный арбитратор, который находится обычно в мосте процессор-PCI, назначает владение шиной PCI. Например, SCSI-контроллер получает данные, вырабатывает за-прос на владение шиной и перемещает данные в центральное ОЗУ методом прямого доступа к памяти. Такой способ передачи данных не требует участия процессора. Операционная система, загруженная на плате системного контроллера, управляет ресурсами без отдельного процессора на их локальной шине PCI (так называемый "глухой" ввод/вывод).
Таким образом, многоабонентская система не обязательно одновременно является и мультиобрабатывающей системой. Шина PCI имеет четыре линии прерывания, которые могут быть использованы несколькими устройствами. Центральный контроллер прерываний располагается непосредственно на локальной шине PCI платы системного контроллера. Такое расположение достаточно для компьютерных систем, однако в системе CompactPCI обработка прерывания происходит несколько сложнее. Стандартная система CompactPCI имеет восемь слотов: если установлены более четырех плат, способных вырабатывать сигналы прерываний, четыре доступных линии прерываний должны распределяться между более чем одним источником прерываний.
Различия в мостах PPB
На практике разработчики соединяют шины PCI различными способами. Первый и наиболее очевидный метод состоит в том, чтобы использовать непосредственное и параллельное соединение связь между локальной шиной PCI и объединительной платой PCI. Очевидное неудобство этого метода ограничение на количество нагрузок, которые модуль PCI может обслу-живать. Обычно это количество не превышает 10. Так как само устройство PCI на материнской плате считается как одна нагрузка, а каждый дополнительный слот считается за две нагрузки, то для стандартного компьютера это означает наличие максимум четырех слотов расширения.
Чтобы избегать этого ограничения, связанного с методом непосредственного соединения, группа PCI Special Interest Group (PCISIG) в 1994 разработала основные спецификации архитектур мостов PPB. Эти спецификации определяют "прозрачный", или "стандартный", мост PPB (рис. 3). После нормальной идентификации в течение процедуры автоконфигурации, мост PPB становится прозрачным по отношению к управляющему процессору. С точки зрения мультиобработки, прозрачный мост ведет себя так же, как и описанная выше прямая связь двух шин PCI. Этот тип PPB не содержит никаких аппаратных ресурсов, например, устройств прямого доступа к памяти (DMA) или регистров (майлбоксов), которые требовали бы наличия отдельного драйвера устройства, а также не преобразует адреса от одной шины PCI к другой.
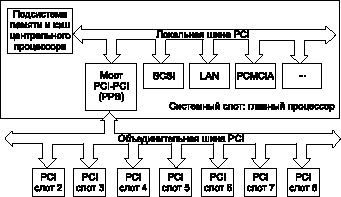
Рис. 3. В базовой CompactPCI архитектуре определяются как "прозрачные", или "стандартные"
При построении стандартной архитектуры CompactPCI на базе слотов с прозрачными мостами PPB, в слот 1 обычно вставляется главная плата системного контроллера, а все микропроцессорные платы ввода/вывода начиная со слота 2 (рис. 4). Мосты PPB каждой платы представляют собой интерфейс между локальной шиной PCI платы и объединительной шиной PCI. Использование прозрачных мостов PPB решает проблему ограничения числа нагрузок шины, но некоторые проблемы мультиобработки при этом остаются.
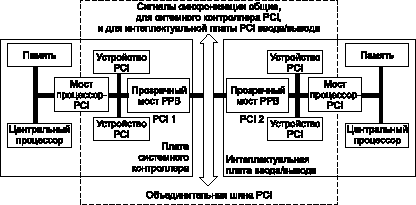
Рис. 4. При использовании прозрачных мостов РРВ в слот 1 стандартной архитектуры системы CompactPCI обычно вставляется плата системного контроллера, а интеллектуальные платы ввода/вывода вставляются в слоты, начиная со второго
Прозрачные мосты PPB не поддерживают технологию plug-and-play, потому что процессы автоконфигурации двух процессоров сталкиваются. После включения питания каждый из процессоров конфигурирует свою локальную подсистему ввода/вывода PCI (PCI1 и PCI2 на рис. 4), свой прозрачный мост PPB, а затем пытается идентифицировать и установить регистры и адресные диапазоны устройств, расположенных на объединительной шине PCI позади моста PPB. Эта ситуация означает, что главная плата не может идентифицировать микропроцессорную плату ввода/вывода и наоборот. Процессоры на системной плате и интеллектуальных платах ввода/вывода, использующих прозрачные мосты, генерируют одинаковые синхросигналы шины PCI и пробуют одновременно управлять объединительной шиной PCI. Кроме того, прозрачный мост не имеет никакого драйвера, который мог управлять коммуникациями (например, майлбоксами) между этими двумя процессорами. Таким образом, вы не можете по крайней мере без значительных дополнительных усилий производить мультиобработку при использовании прозрачных мостов для интеллектуальных плат ввода/вывода в системе CompactPCI или PCI.
Спасение встроенные мосты
Новый тип мостов PPB, встроенный или "непрозрачный", решает проблемы использования нескольких процессоров. Проектировщики разрабатывали их специально для микропроцессорных плат ввода/вывода, и таким образом, для осуществления асинхронной мультиобработки. Использование прозрачного моста PPB на управляющей плате и непрозрачных мостов PPB на интеллектуальных платах ввода/вывода представляет собой аппаратный подход к асимметричной мультиобработке в системах CompactPCI и PCI.
Встроенные мосты реализуют операции plug-and-play без столкновения процедур конфигурации. Встроенный мост эффективно разделяет области, которые сканируют и конфигурируют локальный и главный процессоры. После включения питания процессоры интеллектуальных плат ввода/вывода сканируют или автоконфигурируют их собственные подсистемы ввода/вывода на первичной или локальной стороне встроенного моста. При этом конфигурируется встроенный мост, устанавливаются адресные окна, определяются трансляция адреса и карты адресных регистров для локальных устройств PCI во встроенных мостах с первичной (локальной) и вторичной (объединительной шины) сторон. Диапазон конфигурации локальных процессоров ограничивается встроенным мостом, и поиск устройств на PCI шине объединительной платы не производится (рис. 5).
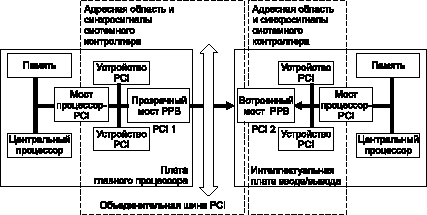
Рис. 5. При ассиметричной мультиобработке с использованием на интеллектуальной плате ввода/вывода встроенного "непрозрачного" моста РРВ, диапазон конфигурации локальных процессоров ограничивается встроенным мостом, и поиск устройств на объединительной шине PCI не производится
Параллельно с конфигурацией плат ввода/вывода при включении питания процессор главной платы конфигурирует локальную подсистему ввода/вывода PCI (PCI1 на рис. 5), прозрачного моста PPB и ищет PCI устройства на шине объединительной платы. Когда процессор находит встроенный мост на интеллектуальной плате ввода/вывода, он видит только вторичную сторону моста, которая выглядит как нормальное целевое устройство PCI, и конфигурирует его соответственно. Управляющий процессор не может видеть внутреннюю шину PCI интеллектуальной платы ввода/вывода (PCI2 на рис. 5).
Использование встроенных мостов также позволяет решить проблему конфликтов адресации за счет преобразования адресов. Например, процессор платы ввода/вывода может "скрывать" ресурсы, необходимые ему самому, от главного процессора системы. Кроме того, преобразование адреса позволяет размещать устройство на локальной шине PCI интеллектуальной платы ввода/вывода по PCI адресу на объединительной шине без каких-либо конфликтов адресации.
Заметим, что встроенные мосты обрабатывают синхросигналы совсем не так, как прозрачные мосты. Главный процессор посылает синхросигнал через его прозрачный мост PPB на объединительную шину PCI и на приложенные устройства PCI. Встроенный мост на интеллектуальной плате ввода/вывода принимает синхросигнал главного процессора на вторичной стороне (объединительной шины), но не пересылает его на первичную сторону (PCI2). Первичная сторона непрозрачного моста работает с синхросигналом, вырабатываемым своим собственным локальным процессором. Оба синхросигнала синхронны относительно своих шин, но асинхронны относительно друг друга.
Непрозрачный PPB также включает в себя майлбоксы и 10 функций "первым пришел первым ушел" (FIFO), обеспечивающие коммуникации между главным процессором и процессором интеллектуальной платы ввода/вывода.
Проблемы прерываний
Теоретически, наиболее существенные ограничения на мультиобработку в реальном масштабе времени накладывает структура прерывания PCI. Шина PCI имеет четыре линии прерывания, которые соединяются с центральным контроллером прерывания. Нижний на рисунке мост PCI-ISA обычно включает в себя центральный контроллер прерываний. При использовании системы со слотами и локальной шиной PCI, изображенной на рис. 3, локальные SCSI, LAN и PCMCIA устройства могут вырабатывать прерывания. Каждое из этих локальных устройств имеет собственную линию прерывания на контроллере прерывания. Например, если контроллер Ethernet (LAN) вырабатывает запрос на прерывание, контроллер прерываний обнаруживает его и посылает процессору. После этого процессор вырабатывает сигнал подтверждения прерывания (IACK) и пересылает его обратно контроллеру прерываний, который определяет начальный адрес требуемой процедуры обработки прерывания. Поэтому система PCI, содержащая до четырех обслуживаемых устройств, может быстро реагировать на внешние события в течение предсказуемого промежутка времени.
В стандартной системе CompactPCI обработка прерывания становится более сложной, потому что прерывания должны обрабатываться даже тогда, когда в системе используется более четырех плат или если какая-либо плата содержит многофункциональное устройство, обслуживающее более одной линии прерывания. Рекомендуемая схема соединений линий прерывания на объединительной плате и их связь с линиями прерывания индивидуальных слотов подразумевает, что линия INTA системного слота соединяется с линией INTB слота 2, линией INTC слота 3, линией INTD слота 4, линией INTA слота 5 и т. д. (рис. 6).
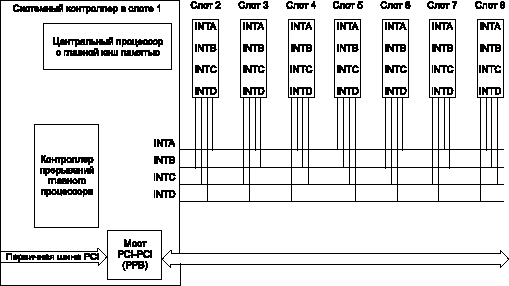
Рис. 6. Рекомендуемая схема соединений линий прерывания на объединительной плате и их связь с линиями прерывания индивидуальных слотов подразумевает, что линия INTA системного слота соединяется с линией INTB слота 2, линией INTC слота 3, линией INTD слота 4, линией INTA слота 5 и т.д.
Чтобы понять, как работает эта система обработки прерываний, предположим, что слоты 3 и 7 содержат простые "однофункциональные" платы с возможностью генерации прерываний. Центральный контроллер прерываний обнаруживает запрос на прерывание от слота 7 и переключает индивидуальную линию INT на процессор. Благодаря обработке вектора прерываний от контроллера прерывания, процессор определяет, что за-прос на прерывание поступил с линии INTC шины объединительной платы. Однако, так как на этой линии находятся две платы, процессор не знает, от какой точно платы пришел запрос на прерывание. Чтобы определить, какая из двух плат является источником запроса на прерывание, процессор должен считать содержимое регистров интерфейсов PCI каждой из этих двух плат. Этот метод обработки прерываний задерживает идентификацию источника прерывания и теоретически подразумевает возникновение ошибочной ситуации: контроллер не сможет распознать запрос на прерывание от платы слота 7, если сразу за ним поступит запрос на прерывание от платы слота 3. Более того, следуя правилам последовательной работы шины PCI, запись данных другой посылки, которые могут все еще быть в FIFO буфере моста PPB платы системного контроллера, должна быть произведена прежде, чем прозрачный мост PPB сделает попытку доступа для чтения на шину CompactPCI. В результате выполнения этого требования расходуется еще большее время.
Обработка прерываний в реальном масштабе времени
Если вы планируете использовать шину PCI для приложений, работающих в реальном масштабе времени, необходимо рассмотреть, соответствует ли применяемая структура прерывания требованиям к быстродействию. При этом в расчет надо брать не только настоящие системные требования, но возможность модернизации ее в будущем. Основным принципом при использовании интеллектуальных плат ввода/вывода должно быть требование снижения нагрузки на главный процессор, локальную обработку прерываний и передачу через шину CompactPCI только необходимых посылок. Процессор интеллектуальной платы ввода/вывода немедленно обрабатывает критически важные прерывания, что делает аппаратные задержки шины CompactPCI, связанные с обработкой прерываний, несущественными. Применение интеллектуальных плат ввода/вывода могут снять требование обработки в реальном масштабе времени с шины CompactPCI и использовать ее только для управления.
Изменения 2.2 к техническим требованиям локальной шины PCI включают так называемые прерывания с сигнальным сообщением (message-signaled interrupt, MSI) для приложений, работающих в режиме реального времени и вырабатывающих большое количество запросов на прерывание. В этом случае для передачи в процессор запроса на обслуживание прерывания MSI имеющиеся четыре линии прерываний на шине CompactPCI не используются. Вместо этого используется метод доступа записи в память по шине CompactPCI в мост PPB, который затем вырабатывает локальное прерывание на плате системного контроллера. Однако эти изменения пока еще окончательно не утверждены.
Программное обеспечение для мультиобработки
Программное обеспечение для описанных выше систем, подобно аппаратному обеспечению, должно поддерживать асимметричные архитектуры мультиобработки. Процессоры должны иметь возможность обмениваться информацией. Один из подходов состоит в том, чтобы использовать общую память, в которую любой из процессоров может записывать данные, благодаря чему осуществляется связь с другими процессорами. Однако, здесь должен существовать механизм, служащий для уведомления других процессоров в том, что данные доступны.
Если системный контроллер должен уведомить интеллектуальную плату ввода/вывода о том, что он запомнил данные для нее в общей области памяти, плата системного контроллера производит попытку регистрового доступа к специальному адресу встроенного моста PPB интеллектуальной платы ввода/вывода (рис. 7). Такой регистровый доступ вырабатывает прерывание на локальной шине PCI платы ввода/вывода. Локальный контроллер прерываний платы ввода/вывода обрабатывает прерывание, и процессор платы считывает данные из общей области памяти. В противоположном направлении процессор интеллектуальной платы ввода/вывода обращается к регистру непрозрачного моста PPB и вырабатывает прерывание CompactPCI, принятое платой системного контроллера. Прозрачный мост PPB передает этот запрос на прерывание непосредственно конт-роллеру прерываний.
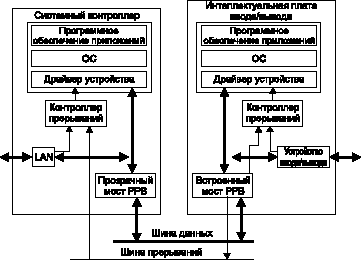
Рис. 7. Если системный контроллер желает уведомить интеллектуальную плату ввода/вывода о том, что он зопомнил данные для нее в общей области памяти, плата системного контроллера производит попытку регистрогового доступа к специальному адресу встроенного моста РРВ интеллектуальной платы ввода/вывода
Некоторые приложения требуют наличия дополнительных средств связи между интеллектуальными платами ввода/вывода. Механизм работы этих связей подобен механизму связи интеллектуальных плат ввода/вывода и системного контроллера. Однако, для достижения этой цели, интеллектуальные платы ввода/вывода должны передать адреса не только общей области памяти, но также и соответствующих регистров (майлбоксов) плат ввода/вывода, с которыми они связываются. Механизм I2O представляет собой альтернативный метод связи двух интеллектуальных плат ввода/вывода.
В данной статье описаны аппаратные требования, накладываемые на систему CompactPCI с целью обеспечить асимметричную мультиобработку. Использование встроенных мостов определяет ключевые требования к системе с мультиобработкой требования на синхронизацию, управление конфигурацией plug-and-play, арбитраж и обработку прерываний. Встроенные мосты также предлагают ряд дополнительных функций, например, организацию регистров (майлбоксов), поддержку механизма I2O и возможность сокрытия ресурсов.
Использование микросхем встроенных мостов и плат ввода/вывода для асимметричной мультиобработки обещает решить некоторые проблемы обработки в реальном масштабе времени систем CompactPCI и PCI. Применение методов такой обработки на заранее определенных интеллектуальных платах ввода/вывода позволяет также решить задачу быстрой обработки прерываний в масштабе всей системы и сводит функции шины PCI или CompactPCI к функциям управления трафиком системы.
EDN, январь 1999 г.
Перевод Ю. Потапова