

Недавно в лаборатории известного журнала для инженеров-разработчиков электронной техники Electronic Design News были проведены исследования ряда микропроцессоров ведущих фирм с целью изучения процесса принятия оптимального решения на системном уровне. Предлагаем нашим читателям ознакомиться с итогами этих исследований.
Реальность системотехники встроенных систем требует таких же реальных решений - это концепция выбора оптимального решения.
Для многих разработок, использующих микропроцессоры, цель не должна состоять в выборе самого производительного из них. Критерием выбора и самого микропроцессора, и подсистемы ввода/вывода является, скорее всего, их способность выполнить определенную работу. И, конечно
же, для принятия правильного решения нет ничего более существенного, чем Ваш личный практический опыт.
С другой стороны, многие производители микропроцессоров обеспечивают разработчиков специальными отладочными платами и средствами, которые позволяют протестировать Ваши теоретические предположения и проверить их практическую реализацию.
В процессе подготовки материалов для этой статьи было проверено множество отладочных плат с целью выяснения их возможностей для облегчения выбора оптимального решения. Однако сложность такой задачи очевидна: многие платы или микропроцессоры предлагают ограниченный набор характеристик, на основании которых нужно сделать выбор.
Итак, основными компонентами этого исследования стали:
- платы IDT79-S465+IDT79-S574 с 250-МГц процессором IDT79RC64575 фирмы IDT,
- платы M30620TB-RPD-E и комплект MSA0600 с 16-МГц M16C/62A процессором фирмы MITSUBISHI;
- платы NEC - Midas RTE-V832-PC с 143-МГц V832 и DDB-VRC5074 с исправленной версией 4.0 250 МГц VR5000, а также STi5500- DEMO с 50-МГц процессором ST20C2 фирмы STMICROELECTRONICS.
В процессе сравнения платы проверялись по тестам EEMBC (Консорциум по быстродействию встроенных микропроцессоров) при различных вариантах их конфигурации, выключенной кэш-памяти и различных вариантах компиляции программ. Для облегчения анализа все полученные результаты были пронормированы.
Со стандартами EEMBC и их описанием можно ознакомиться на сайте сертификационной лаборатории EEMBC (www.embedded-benchmarks.com), а со сравнительными характеристиками - по адресу www.eembc.org/benchmark.
Для экспериментов с продукцией
фирмы MITSUBISHI использовались тесты EEMBC для авто- и промышленной электроники. Объектом исследования стал микропроцессор M16C/62A, установленный на эмуляторе PC4701 и содержащий M30620TB-RPD-E ┼ синхронную динамическую память (SDRAM) с нулевым состоянием ожидания.
Согласно описанию, M16C/62A -
16-разрядный CISC-микропроцессор. Формат его команд позволяет передавать данные между любыми двумя регистрами в пределах центрального процессора или 1-Мбайт адресного пространства. Имеется также возможность выбора пользователем 8- или 16-разрядной шины данных и команд побитовой обработки.
В качестве компилятора использовался фирменный компилятор NC30 версии 3.20 вариант 1.
Для M16C он является достаточно простым, но это позволяет легко проверить все опции, включая использование модели верхней памяти, эффективность программ как при оптимизации по размеру, так и без оной. В регистре конфигурации был установлен один цикл ожидания при обращении к памяти процессора (Processor Mode Register = 1 в файле инициализации).
К сожалению, один полезный режим, который не был установлен, мог бы продемонстрировать различия в быстродействии 8- и 16-разрядной шин памяти. Но для этого необходимо было бы установить M16C/62 в микропроцессорный режим с использованием внешней памяти, а также поменять аппаратные установки в самом эмуляторе и изменить EEMBC-коды.
Данные для M16C/62 нормировались по максимальному значению производительности в пределах каждого теста. Так, например, наибольшая производительность достигается при побитовой обработке: это принимается за 1, а другие результаты составляют лишь некоторую ее долю.
Компиляция в режиме оптимизации
программы по размеру дала незначительный прирост производительности и минимально, но влияет на размер программы. Например, при инверсии дискретного косинус-преобразования, уменьшение размера программы составило всего 1%. А вот компиляция с использованием модели верхней памяти ( far-memory) более серьезно влияет на производительность. Однако использование этой модели эффективно только при наличии памяти больше 64 Кбайт и требует применения 32-разрядных указателей, которые, однако, приводят к дополнительным потерям производительности, поскольку приходится манипулировать 32-разрядными данными, использующими 16-разрядные регистры. Например, если адрес требует более чем 16-разрядного указателя (как это имеет место в модели верхней памяти), центральный процессор должен выполнять операции отдельно для младших и старших полуслов. Вместе с тем, если центральный процессор читает или пишет данные больше, чем 64 Кбайт, но не изменяет при этом указатель адреса, уменьшения производительности не происходит. Таким образом, использование модели верхней памяти более всего снижает производительность по
сравнению с другими причинами, исследуемыми в данном случае, и может
составить более 60%. Такое снижение является результатом обработки большего объема данных и обусловлено необходимостью распространенной обработки указателя. Тем не менее, эти данные говорят о том, что нужно оценивать необходимость использования памяти данных более 64 КБайт индивидуально для каждого случая, поскольку модель верхней памяти не всегда так значительно влияет на другие показатели.
Выключение всех видов оптимизации компилятора дает очень интересные результаты (рис. 1).
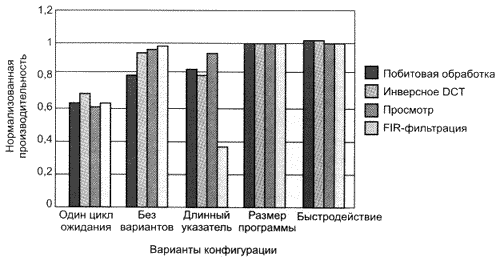
Рис. 1. Результаты тестов для микроконтроллера M16C/62A
За исключением тестов побитовой
обработки, производительность упала не менее чем на 7%.
К сожалению, отсутствуют точные
данные, объясняющие этот эффект, но существуют различные потенциально
правдоподобные теории. Будем исходить из того, что изначально компилятор и процессор вместе работают нормально, и компилятор автоматически осуществляет многие виды оптимизации.
Однако, поскольку мы получили
ухудшение производительности, используя тесты EEMBC, они, по-видимому, имеют какой-то существенный недостаток, воздействуя таким образом на оптимизационную эффективность компилятора. Если недостатки тестов являются тому виной, то микроконтроллеры M16C/62 должны продемонстрировать значительное улучшения производительности после того, как инженеры фирмы MITSUBISHI усовершенствуют
формат тестовых данных EEMBС.
С другой стороны, производительность процессора упала на 21% и при отключении оптимизации для тестов побитовой обработки. Фирма MITSUBISHI утверждает, что это падение является результатом операций, производимых процессорами и компиляторами с маскированными битовыми указателями и операциями сдвига.
В другом эксперименте был изучен целый ряд конфигураций с использованием тестов EEMBC для JPEG-сжатия и передачи стандартных пакетов данных в сетях.
Тест JPEG-сжатия делит изображение на блоки размером 8x8 пикселей и вычисляет дискретные значения косинуса преобразования (DCT) для каждого блока. После чего коэффициенты DCT округляются согласно матрице квантования. В соответствии с технологией сжатия, в этих коэффициентах используется код переменной длины, после чего сжатый поток данных записывается в память.
Тест потока пакетов данных представляет собой 2-Мбайт поток, который принимается и обрабатывается
соответствующим образом. Оба теста оперируют с большими объемами неповторяющихся данных, что минимизирует преимущества кэширования.
Работа с микроконтроллерами фирмы STMICROELECTRONICS началась с прогона ST20C2 на частоте 50 МГц. Этот 32-разрядный RISC-процессор имеет память программ и кэш-данных объемом 2 Кб, а также 16-разрядный интерфейс внешней памяти. В этой конфигурации использо-
валась 50-МГц шина памяти со схемой доступа 4-3-3-3. Для компиляции программ EEMBC-тестов использовался компилятор STMicro ST20 ANSI Версии 1.8. Исключение команд обработки кэш-данных уменьшало производительность на 50▄70%, в зависимости от теста, хотя простое отсутствие кэш-данных приводило к снижению ее всего на 21% (рис. 2). (Показатели JPEG и потока пакетов нормированы независимо от друг друга.)
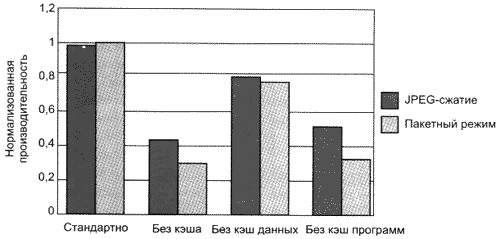
Рис. 2. Результаты для ST20 в рамках JPEG-сжатия и передачи сетевых пакетов для различных вариантов кэш
Другая интересная особенность
проявилась при анализе работы с микроконтроллером NEC V832: оказалось, что большее падение производительности наблюдается в более быстром процессоре с большим объемом кэш-памяти.
Если сравнить процессорные ядра
(ST20C2 и NEC V832) и пронормировать их независимо друг от друга, то
получается, что при отключении кэш-памяти производительность V832 упала на 92% (рис. 3).
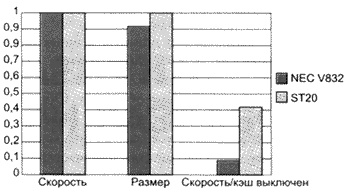
Рис. 3. Сравнение результатов для ST20 и V832
V832 представляет собой 143-МГц, 32-разрядный RISC-процессор с 4-Кб внутренней памятью команд и кэш-памятью данных.
Для компиляции тестов EEMBC в этом случае использовался компилятор фирмы GREEN HILL SOFTWARE NEC V800 версии 1.8.9. Причем с отключенной кэш V832 работает на частоте внешней шины.
Для V832 была скомпилирована программа теста JPEG-сжатия, оптимизированная по размеру (размер уменьшился на 12 Кб - с 36118 до 24842 Байт), который показал уменьшение производительности на 8%.
Отладочная плата для процессора V832 - Midas RTE-V832-PC позволяет легко изменять разрядность внешней шины от 16 до 32 бит. Контрольные тесты JPEG и потока пакетов данных проводились для двух этих
конфигураций (рис. 4). Нормировка каждого теста проводилась по максимальному значению производительности.
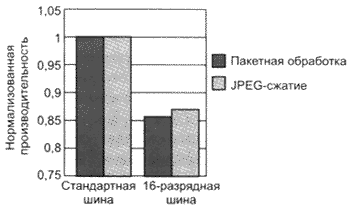
Рис. 4. Разрядность шины играет большую роль в производительности (на примере V832)
Для обоих тестов уменьшение
производительности составило соответственно 12 и 14% - на практике это будет зависеть от конкретных инженерных решений разработки, а экономия на стоимости памяти может стать оправданием снижения производительности.
Частота или память?
Тест для процессора IDT 79RC64575 проводился на комбинации фирменных материнской и отладочной плат: IDT79S465
и IDT79S574. Процессор 79RC64575 представляет собой 64-разрядный RISC-процессор на базе MIPS-ядра. Используемый для тестирования процессор имеет рабочую частоту 250 МГц, работает с 50-МГц шиной памяти и содержит 32 Кб памяти команд и кэш
данных.
В эксперименте использовался компилятор фирмы IDT версии GNU.
Анализ результатов теста на обработку потока пакетов данных показал, что при уменьшении вдвое разрядности 64-разрядной внешней шины производительность этого процессора падает на 20%. Аналогично, производительность упала на 94% при выключении кэш-памяти.
(Строго говоря, для всех трех MIPS-
процессоров, использованных в этом исследовании, кэш-память не отключалась. Вместо этого файл связи модифицировался таким образом, что монитор ПЗУ загружал программу и данные в некэшируемую область памяти.)
Отладочная плата процессора IDT может содержать как SDRAM, так и SRAM со схемой доступа 7-1-1-1 для режима записи и 3-1-1-1 для режима чтения. Модифицируя файл связей, можно разместить тестовую программу и данные или в SDRAM или в SRAM. Перемычки на плате также позволяют изменять частоту процессора, хотя при этом скорость передачи данных по шине
памяти остается постоянной (рис. 5).
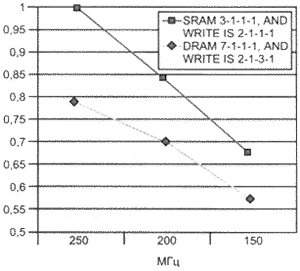
Рис. 5. Влияние типа памяти, времени доступа и рабочей частоты процессора на производительность
Стоит обратить внимание, что кривая производительности почти линейна для обоих вариантов: и для SDRAM, и для SRAM. Однако характеристика быстродействия памяти (или так называемое время доступа) становится более критичной в области высоких частот и приводит к потерям производительности до 21% по мере приближения к 250 МГц. Сравните эту цифру с 9% потерь производительности на 150 МГц!
А еще заметьте, что 20-% падение
производительности эквивалентно переходу на 32-разрядную шину памяти; эта цифра дает возможность оптимального выбора при реализации новой разработки.
Результаты сетевых тестов
Сетевые тесты EEMBC проверялись
на плате BMU3927JMR с 32-разрядным MIPS-процессором TX3927 фирмы TOSHIBA.
TX3927 работает на частоте 133 МГц, содержит 4 Кб кэш-памяти команд, 2 Кб кэш-памяти данных и использует 66-МГц внешнюю шину со схемой доступа 5-1-1-1.
В работе использовался компилятор Green Hills Multi2000 Версии 2.0. Результаты приведены на рис. 6.
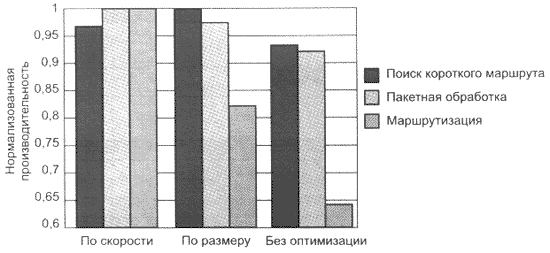
Рис. 6. TX3927 демонстрирует зависимость производительности от алгоритма оптимизации
В дополнение к проверке быстродействия обработки пакетов данных, тестирование включало тесты на маршрутный поиск и выбор самого короткого маршрута (OSPF).
Наиболее интересным оказался тот
факт, что скорость OSPF повышалась при оптимизации тестовой программы по размеру. Единственное логическое объяснение этому состоит в том, что компилятор, сохраняя размер программы, минимизирует количество циклов. Скорость маршрутного поиска более всего оказалась зависима от оптимизации программы по скорости, снизившись на 18 и 35%, соответственно, при включенной и выключенной оптимизации. Аналогично V832 и другим MIPS-процессорам, производительность TX3927 падала более, чем на 90%, когда не использовалась кэш-память.
Говоря о кэш, хочется рассказать о
проверке некоторых протоколов работы с ней на примере NEC VR5000. Измерялась производительность процессора при использовании двух протоколов записи данных: write-back (перезаписи) и write-through (сквозной записи).
Установки для VR5000 были аналогичны установкам для IDT 79RC64575. Процессор работал на частоте 250 МГц, имел 32 Кб памяти команд и кэш-память данных, но использовалась 100-МГц системная
шина памяти.
Подобно варианту с TOSHIBA, использовался компилятор Multi2000 Версии 2.0.
При этом в режиме сквозной записи для тестов потока пакетов данных и JPEG-сжатия, производительность упала на 42 и 69%, соответственно. В случае с JPEG производительность оказалась более низкой из-за большого числа операций последовательной записи. Также JPEG-алгоритм использует 16-разрядные данные, что, конечно же, неэффективно для 64-разрядного процессора. (В этом случае может помочь оптимизация тестов).
Аналогичные результаты для EEMBC-тестов DCT показали, что в режиме сквозной записи (write-through)
производительность падает почти на 60%. В этом режиме запись в кэш-память производится через основную память, что требует расширения полосы частот. С другой стороны, режим перезаписи (write-back) уменьшает число обращений к памяти ядра процессора, но требует больше логических операций. Это является причиной того, что этот режим приводит к большим потерям производительности, хотя многие
процессоры и не используют его. Итак, хотя многие результаты, полученные в этом исследовании, кажутся очевидными, всегда полезно иметь количественные показатели, нежели полагаться на ощущения.
Кроме того, стандартизация EEMBC-
тестов гарантирует, что все процессоры выполняли одни и те же тесты.
В идеале, нужно было бы опробовать эти тесты со значительно большим разнообразием процессоров, компиляторов и конфигураций. Но, к сожалению, реализация многих конфигураций была невозможна, как и доступность многих инструментальных средств.
Например, было бы полезным иметь возможность изменять размер кэш-памяти процессора, чтобы определить "перегиб" на графике, где производительность начинает падать.
Однако в реальных аппаратных средствах изменение размера кэш-памяти требует блокировки ее нижних областей, создавая при этом фактически меньшую кэш-память. Было бы также неплохо иметь возможность варьировать числом состояний ожидания или разрядностью внешней
шины для тех процессоров, которые были здесь использованы.
Применение симуляторов вместо
реальных аппаратных средств, возможно, дало бы много больше экспериментальной информации. Но...нельзя объять необъятное.
Перевод А. Биленко